“Attention Is All You Need” is a groundbreaking research paper published in 2017 by 8 scientists from Google. This paper introduced the transformer, a new deep learning architecture built on the attention mechanism first proposed by Bahdanau et al. in 2014. Regarded as a foundational work in modern artificial intelligence, the transformer architecture has become central to large language models, including those based on GPT. Initially focused on enhancing Seq2Seq techniques for machine translation, the authors also envisioned the broader potential of this approach for various applications, including question answering and what is now referred to as multimodal Generative AI.
Click Here To Read “Attention Is All You Need”
- What’s in it for me?:
- The paper introduces the Transformer, a new architecture based on attention mechanisms. It eliminates the need for recurrence and convolutions, leading to faster training and higher parallelization. Experiments on translation tasks show superior performance. The model achieves state-of-the-art results in BLEU scores.
- When was it carried out? Are the results still relevant?:
- The research was published in 2017 during the 31st Conference on Neural Information Processing Systems (NIPS). It is highly relevant today as the Transformer architecture has become a foundation in various AI fields. Transformers continue to dominate sequence transduction tasks. Their relevance has expanded beyond translation to other tasks like parsing and summarization.
- Where was it carried out?:
- The study was conducted primarily by researchers from Google Brain and Google Research, with additional contributions from the University of Toronto. Experiments were carried out using the WMT 2014 English-German and English-French translation tasks. The team utilized 8 NVIDIA P100 GPUs for training. Their infrastructure allowed for high-efficiency parallel processing and model training.
- Who did the study? What is their track record? What do they stand for?:
- The study was conducted by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, and Illia Polosukhin. All are recognized experts in machine learning, particularly in deep learning and attention mechanisms. Their contributions in AI include advances in machine translation and neural networks. They stand for innovation in efficient neural architectures.
- Who is it aimed at? Who are the target audience? What is the rhetoric like? How is the argument constructed? How do they sell the basic idea?:
- The paper targets AI/ML researchers and professionals, particularly those working in natural language processing and sequence modeling. The rhetoric is technical and precise, focusing on the architectural benefits of attention over traditional methods. The argument is constructed by comparing performance results on standard benchmarks. They sell the idea by demonstrating faster training and higher accuracy with the Transformer.
- What images and metaphors do the authors draw upon? Is it meaningful? (Clarity of language, concepts used):
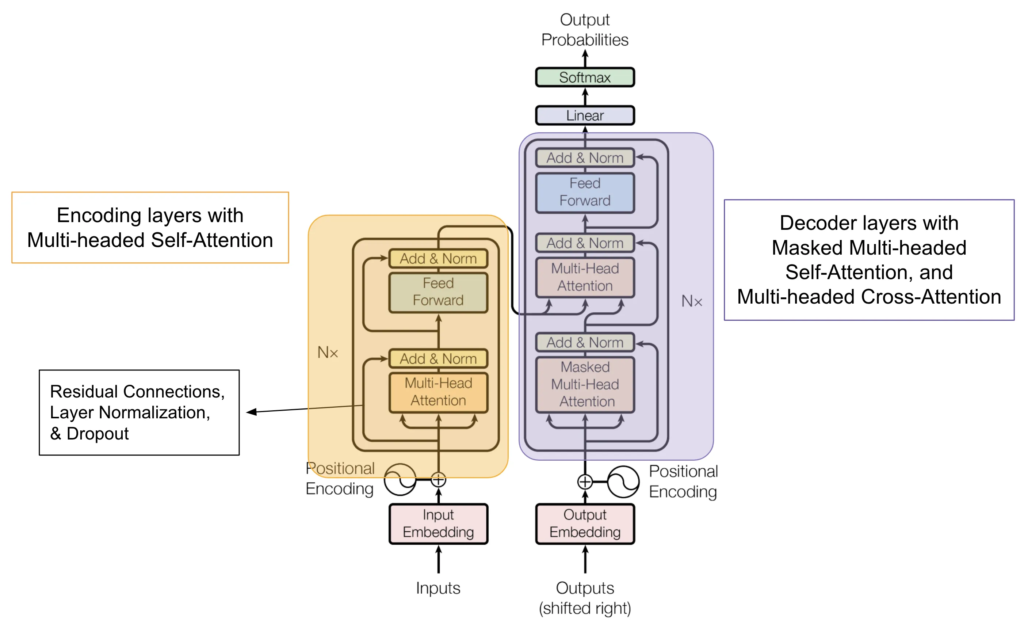
- The paper uses diagrams to illustrate the architecture of the Transformer, such as attention layers and model flow. They present clear visual representations of attention heads and attention distribution patterns. Figures 1 and 2 provide clarity on the model’s functioning. The images support the text, enhancing understanding of multi-head attention.
- Is the literature review adequate? Are they missing anything out? Why?:
- The literature review is comprehensive, addressing the limitations of recurrent neural networks (RNNs) and convolutional neural networks (CNNs). It mentions previous advancements in attention mechanisms used alongside RNNs. The authors introduce the novel concept of using attention without recurrence or convolutions. They adequately cover existing models and justify their approach.
- Does the literature review clearly tell us what is already known about the topic?:
- Yes, the literature review covers what is already known, particularly regarding sequence transduction models. It highlights the weaknesses of RNNs in terms of sequential computation and memory constraints. Attention mechanisms are discussed as an improvement for handling long-range dependencies. The review provides context for the necessity of the Transformer model.
- What is the theoretical perspective that is being used? How might this perspective distort the phenomenon?:
- The theoretical perspective is centered on self-attention mechanisms and their ability to model dependencies across sequences. This perspective shifts the focus away from sequential computation, which may neglect the importance of local dependencies. The use of attention allows for global context modeling. However, removing recurrence may lose the benefits of temporal sequence information.
- What other theoretical perspective(s) might be applied?:
- Other theoretical perspectives, such as recurrent neural networks (RNNs) or convolutional neural networks (CNNs), might be applied. These models handle sequential data more explicitly, with RNNs focusing on temporal dependencies. CNNs are used for local feature extraction. While attention offers global context, these alternatives might capture local relationships more effectively.
- What is the sample? Is the sample representative of the underlying population?:
- The sample consists of standard datasets used in machine translation, particularly WMT 2014 for English-German and English-French tasks. These datasets are widely accepted benchmarks in the machine translation community. The sample size is large, with millions of sentence pairs for training. The use of standard datasets ensures that the results are representative of real-world translation tasks.
- Is the sample culturally biased in some way? How might this distort the findings and conclusions?:
- The datasets used are limited to Western languages, specifically English, German, and French. This may introduce cultural biases, as language-specific nuances may not be captured. The results may not generalize to non-Western languages, such as those with different syntactic structures. This cultural bias could affect the model’s performance on other language pairs.
- Where does the study stand in relation to social justice?:
- The study does not directly address social justice concerns. It is primarily focused on improving model performance in sequence transduction tasks. There are no explicit mentions of fairness or inclusivity in the context of language models. The research is technical and performance-driven, with no social implications discussed.
- Where is the voice of the client/research participant?:
- There is no direct involvement of clients or research participants in this study. The research is conducted entirely within the realm of machine learning, focusing on algorithmic improvements. It relies on pre-existing datasets for evaluation. No human participants are directly engaged in the research process.
- What was the purpose of the study? Was there a hidden agenda?:
- The purpose of the study was to introduce a novel architecture for sequence transduction tasks that eliminates the need for recurrence and convolution. There is no indication of a hidden agenda; the goal is to demonstrate the effectiveness of the Transformer model. The study focuses on achieving better performance with faster training times. It is a straightforward attempt to push the boundaries of current models.
- Who were the researchers? What were they trying to prove? Could they have been biased? In what directions?:
- The researchers are Ashish Vaswani, Noam Shazeer, and colleagues, all of whom are prominent figures in machine learning. They aimed to prove that self-attention can replace RNNs and CNNs in sequence transduction. Their bias might lean towards demonstrating the superiority of attention mechanisms. However, they provide empirical evidence to support their claims, minimizing bias.
- How reflexive and transparent are the researchers, in terms of acknowledging their own pre-assumptions, expectations, professional interests and experience, etc?:
- The researchers are transparent in presenting their methodology and motivations for exploring self-attention mechanisms. They openly discuss the limitations of previous models and the inspiration behind the Transformer. The authors acknowledge that their approach builds on existing work in attention mechanisms. There is no indication of withheld assumptions or expectations.
- Is this study mainly a PR exercise, intended to promote a particular school of therapy, or were the researchers genuinely open to making new discoveries or challenging existing theories?:
- The study is not a PR exercise. It is a genuine contribution to the field of machine learning, particularly in advancing sequence transduction models. The researchers were open to exploring new architectures and challenging the dominance of RNNs and CNNs. Their work has led to significant advancements in AI, particularly in natural language processing.
- What questions (hypotheses) were they asking?:
- The primary hypothesis was that a model architecture based entirely on attention mechanisms could outperform existing RNN- and CNN-based models in sequence transduction tasks. They questioned whether self-attention could model dependencies more effectively. The researchers also sought to prove that the Transformer could reduce training time. The hypothesis focused on both performance and efficiency improvements.
- Were these the best questions? What other questions might have been pursued?:
- These were appropriate questions for the time, especially given the limitations of RNNs in handling long-range dependencies. Other questions could have explored the generalizability of the Transformer to non-language tasks. Additionally, questions regarding the model’s performance on low-resource languages or different modalities (e.g., audio, video) could have been pursued.
- What methods did they use? Why did they choose these methods?:
- The researchers used machine translation tasks to benchmark the performance of the Transformer. Specifically, they employed the WMT 2014 English-German and English-French datasets. These tasks were chosen because they are standard benchmarks in the field. The use of BLEU scores provided a clear metric for comparing translation quality across models.
- Could other methods have produced a different set of results?:
- Using different tasks, such as speech recognition or image captioning, might have produced different results. While the Transformer excelled in machine translation, it may behave differently in non-textual domains. Other methods, such as hybrid models combining attention with recurrence, might yield alternative insights.
- What procedures did they adopt? What was the experience of participants? Could they have been trying to please, or to frustrate, the researcher?:
- There were no human participants involved in the study. The procedures focused on training and evaluating models on machine translation tasks. The researchers followed standard training and evaluation protocols. The experience of the models is purely algorithmic, and there is no concern about bias or intent to please.
- Do the measures being used adequately reflect the phenomenon as you have experienced it, or as you might imagine it to be?:
- The measures, particularly the BLEU score, are standard in machine translation research. They adequately reflect translation quality and are widely used in the field. The use of BLEU scores is appropriate for assessing the phenomenon of translation accuracy. It is a well-established metric for this type of task.
- How were data analyzed? Are you given enough information to follow what the researcher(s) handled and analyzed the data?:
- Data analysis focused on comparing BLEU scores across different models and configurations. The researchers provide detailed results for both the base and big Transformer models. They also compare their results with previous state-of-the-art models. The analysis is transparent and well-documented, allowing for reproducibility.
- Are there any inconsistencies in the results?:
- No inconsistencies are noted in the results. The findings consistently show that the Transformer outperforms RNN- and CNN-based models in both translation quality and training time. The results align with the researchers’ claims. There are no contradictions or unexplained discrepancies.
- Are there any odd or outlier results that are not picked up or commented on by the authors?:
- There are no major outliers in the results that go unaddressed. The researchers provide explanations for the performance differences between the base and big models. They also discuss the trade-offs involved in model size and training time. No significant anomalies are overlooked.
- What distinguishes the results from common-sense?:
- The results challenge the common-sense notion that more complex models (i.e., RNNs with recurrence) are always better for sequence tasks. The Transformer, with its simpler attention-based architecture, outperforms more complex models. This defies the expectation that recurrence is necessary for sequence transduction. The findings show that attention can replace recurrence without loss of performance.
- How clearly is it written?:
- The paper is well-written but highly technical, making it accessible primarily to those with a background in machine learning and sequence modeling. The descriptions of the model architecture and attention mechanisms are clear and detailed. Diagrams help to clarify the concepts. Overall, the clarity is good for the intended audience.
- Does the discussion clearly tell us how this study adds to what is already known about this topic?:
- Yes, the discussion highlights how the Transformer advances the field by eliminating the need for recurrence and convolution in sequence transduction. It emphasizes the performance improvements and training efficiency. The authors also discuss how their work builds on existing attention mechanisms. The discussion effectively positions the Transformer as a breakthrough in the field.
- What are the conclusions? Do the conclusions follow logically from the findings?:
- The conclusions are that the Transformer model outperforms RNN- and CNN-based models in sequence transduction tasks, particularly in machine translation. The researchers conclude that attention mechanisms alone are sufficient to model dependencies. These conclusions follow logically from the experimental results. The findings support the claims made in the conclusion.
- How did they interpret their findings?:
- The researchers interpret their findings as evidence that self-attention mechanisms can replace recurrence and convolutions in sequence modeling. They emphasize the efficiency gains in training and the improved parallelization. The findings are presented as a significant improvement over existing models. The interpretation is focused on the practical benefits of the Transformer architecture.
- Are there any plausible alternative competing interpretations that might be offered?:
- One alternative interpretation could be that the success of the Transformer is specific to machine translation tasks and may not generalize to other types of sequence tasks. Another interpretation could question whether the improvements are due to attention mechanisms alone or the overall architecture, including other components like feed-forward networks.
- How clear, and necessary, are the diagrams and tables?:
- The diagrams and tables are clear and necessary for understanding the model architecture and performance metrics. Figure 1, showing the Transformer architecture, is particularly important for visualizing the model’s structure. The tables comparing BLEU scores provide a clear comparison of performance across models. These visual aids are essential for following the technical content.
- How capable of replication is the study? Has it already been done?:
- The study is highly replicable. The authors provide detailed descriptions of their methods and hyperparameters. Additionally, the code for training and evaluating the Transformer is available online. The Transformer architecture has been widely adopted and replicated in various research and industry applications since its publication.
- How useful is the references/bibliography? Which references might I want to follow up?:
- The references are comprehensive, including foundational works in attention mechanisms, sequence modeling, and machine translation. Key references to follow up include Bahdanau et al. (2014) on neural machine translation with attention, and Vaswani et al.’s earlier works on attention mechanisms. These references provide a solid foundation for understanding the development of the Transformer.
- Will it lead to further research? What needs to be done next?:
- The paper has already led to significant further research, particularly in natural language processing and transformer-based models like BERT and GPT. Future research could explore the application of the Transformer to other domains, such as video or audio processing. Another avenue of research could involve optimizing attention mechanisms for very long sequences.
- Whose voice is being heard in this paper? Who holds power and authority?:
- The voice of the AI research community is dominant, with the authors representing leading institutions like Google Brain and Google Research. The authors, as recognized experts in machine learning, hold power and authority in the discussion. Their work has influenced the direction of AI research, particularly in the development of attention-based models.
- Are the implications for practice discussed adequately? Do you agree with what is said about implications for practice?:
- The implications for practice are discussed adequately, particularly in terms of the performance and efficiency gains offered by the Transformer. The authors emphasize how the model can be used to improve machine translation systems. The practical implications are clear, and the results have been validated in real-world applications. The discussion aligns with current trends in AI practice.
“Attention Is All You Need” by Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan Gomez, Lukasz Kaiser, and Illia Polosukhin.