LLMs (Large Language Models) are advanced AI systems trained to understand, generate, and manipulate human language. They are built on neural networks, specifically Transformers, which have transformed natural language processing (NLP). Here’s how they work at a high level:
1. Architecture: Transformer Model
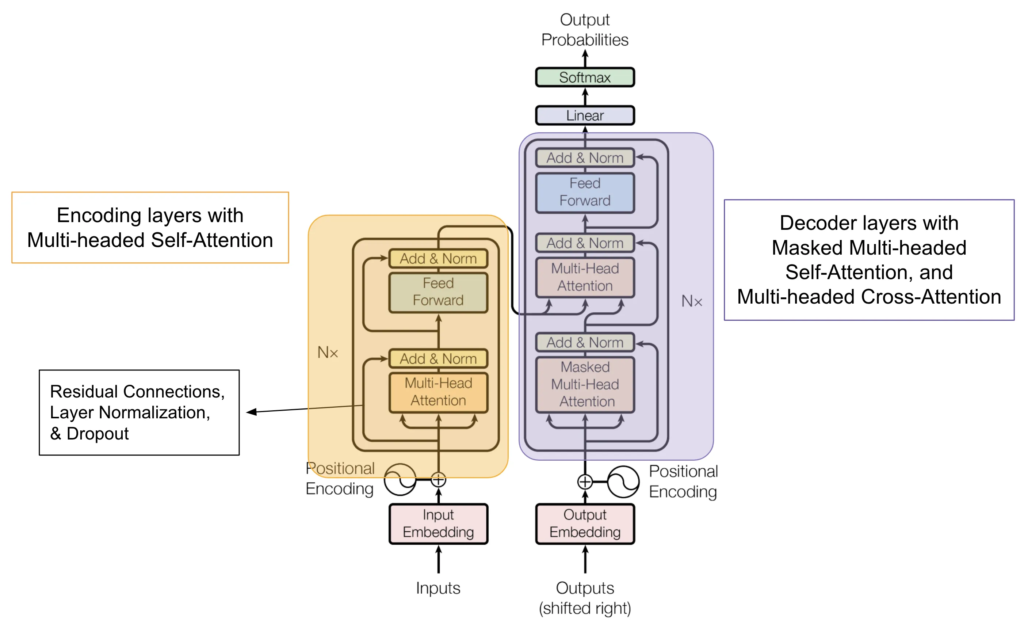
- LLMs are based on Transformers, which are neural network architectures designed to handle sequential data, like text. Unlike older models (RNNs and LSTMs), which process data in order, Transformers process entire sequences at once, making them highly efficient.
2. Key Components:
- Self-Attention Mechanism: This allows the model to weigh the importance of each word in a sentence relative to others. For example, in the sentence “The cat sat on the mat,” the model can understand that “the mat” is more closely related to “sat” than to “cat.”
- Positional Encoding: Since Transformers don’t read text sequentially, they rely on positional encoding to understand the order of words in a sentence, helping them capture the meaning of text more effectively.
3. Training Process
LLMs are trained on massive amounts of text data, using unsupervised learning techniques. Here’s how:
- Pretraining: The model is exposed to vast corpora (e.g., books, articles, websites) to learn patterns in language. It learns to predict the next word in a sentence (language modeling) or fill in blanks in text (masked language modeling).
- Fine-tuning: After pretraining, the model is fine-tuned on more specific datasets to perform tasks like translation, summarization, or Q&A.
4. Inference (How They Generate Responses)
Once trained, LLMs can generate text by predicting one word at a time. They sample from the most likely next word based on the context and continue until the output is complete. This allows them to generate human-like sentences, paragraphs, and even full essays.
5. Large Scale (Bigger is Better)
LLMs like GPT-4 or GPT-3 have billions or even trillions of parameters. These parameters are essentially weights that the model learns during training to capture the relationships between words. The larger the model, the better it can capture nuances in language.
6. Applications
LLMs are used in various applications:
- Text generation: Writing essays, stories, reports
- Translation: Converting text from one language to another
- Summarization: Condensing long documents into summaries
- Q&A: Answering questions based on context or existing information
7. Challenges
- Bias: Since LLMs are trained on real-world data, they can inherit biases present in the data.
- Resource Intensive: LLMs require significant computational power and resources to train, limiting accessibility.
- Hallucination: They may generate plausible-sounding but incorrect information.
Here is a detailed video regarding how transformers work actually?
Definition of GPT:
GPT stands for Generative Pretrained Transformer. It generates new text based on prior training on vast amounts of data, allowing for further fine-tuning on specific tasks.
Transformers:
The core invention driving modern AI, originally introduced in 2017 by Google for text translation, transformers can process various data types, including text, audio, and images.
Prediction Mechanism:
GPT models, such as ChatGPT, are designed to predict the next word in a text sequence. This is achieved by feeding the model a snippet of text, which generates a probability distribution over possible next words. The model samples from this distribution to generate longer text.
Text Generation Process:
The process involves repeated prediction and sampling. Initial input is tokenized into manageable pieces (tokens), each associated with a vector that encodes its meaning. The tokens interact through attention blocks, which help update their meanings based on context.
Neural Network Structure:
The video outlines the flow of data through attention blocks and multi-layer perceptron layers, emphasizing that the final vector represents the passage’s meaning. Operations such as matrix multiplication are central to these processes.
Chatbot Implementation:
For chatbots, a system prompt establishes the interaction setting, with user input guiding the model’s responses.
Exploration of Word Embeddings:
- The discussion focuses on how word embeddings capture relationships and similarities between words.
- An example highlights how manipulating embeddings can relate different concepts, like combining Germany and Japan embeddings with sushi to approximate bratwurst.
Dot Product Intuition:
- The dot product of two vectors indicates how well they align.
- Positive dot products suggest similar directions, zero indicates perpendicularity, and negative values indicate opposite directions.
Plurality Direction:
- Testing the vector representing “cats” minus “cat” shows that plural nouns yield higher dot product values, indicating alignment with the plurality direction.
- A pattern emerges where plural forms score higher, allowing quantitative measurement of how plural a word is.
Embedding Matrix:
- GPT-3 has a vocabulary of 50,257 tokens, represented in a matrix with 12,288 dimensions, totaling approximately 617 million weights.
- These embeddings encode individual word meanings and can also absorb context during processing.
Contextual Understanding:
- Vectors evolve throughout the model, absorbing rich and nuanced meanings based on context, rather than representing isolated word definitions.
- The goal of the network is to incorporate context efficiently for accurate predictions.
Fixed Context Size:
- GPT-3 utilizes a fixed context size of 2048 tokens, limiting the amount of text it can incorporate when predicting the next word.
- Long conversations may result in loss of coherence due to this limitation.
Final Prediction Mechanism:
- The model outputs a probability distribution over potential next tokens.
- The last vector in context is transformed through a matrix (Unembedding matrix) to predict the next word.
Unembedding Matrix:
- This matrix has a row for each vocabulary word and mirrors the embedding matrix, adding approximately 617 million parameters.
- It contributes to the total parameter count, which aims for 175 billion in total.
Softmax Function:
- Softmax transforms arbitrary lists of numbers into valid probability distributions.
- It ensures that outputs are between 0 and 1 and sum to 1, providing a mechanism to determine likely next words in the sequence.
Mechanism of Softmax:
- The process involves exponentiating each input number, resulting in a list of positive values, which are then normalized by dividing by their sum.
- This method emphasizes the largest values, making them more significant in the resulting distribution.
Temperature Control in Softmax:
- GPT-3’s sampling method introduces a concept called temperature (t), which adjusts the “creativity” of the output. A lower temperature forces the model to pick the most probable next word, leading to predictable results. A higher temperature introduces more randomness, making the output more creative but also more prone to generating nonsense. The maximum allowed temperature is capped at 2 for stability reasons.
Logits and Probabilities:
- The model outputs raw, unnormalized scores known as logits before applying softmax. These logits represent the likelihood of each word being the next in sequence. After passing through softmax, the logits are converted into normalized probabilities, from which the model can sample the next word.
Introduction to Attention Mechanism:
- The discussion wraps up by teasing the next chapter, which delves into the attention mechanism, a crucial innovation in modern AI architectures. With a foundation built on understanding embeddings, softmax, and matrix operations, the attention mechanism’s role should be clearer. This next chapter is highlighted as the cornerstone of current AI advances, marking a transition to deeper topics.
Get started with HuggingFace
Transformer Architecture
Google On Transformers: Understand the model behind GPT, BERT, and T5
Summary about the video:
This video transcript introduces the concept of transformers, a type of neural network architecture that has transformed the fields of natural language processing (NLP) and machine learning. Dale Markowitz explains how transformers, like BERT, GPT-3, and T5, revolutionized tasks such as text translation, generation, and even biology-related problems like protein folding.
Before transformers, models like Recurrent Neural Networks (RNNs) struggled with long sequences of text and were slow to train due to their sequential nature. Transformers, developed in 2017 by Google and the University of Toronto, addressed these issues by using parallelization to speed up training and handle vast datasets. This breakthrough allowed models like GPT-3 to be trained on massive datasets, such as 45 terabytes of text, leading to impressive results in generating poetry, code, and more.
The video highlights three key innovations of transformers:
- Positional Encodings: Instead of processing words sequentially like RNNs, transformers embed information about word order directly into the data using positional encodings. This helps the model learn word order from the data itself.
- Attention Mechanism: Attention allows the model to focus on different parts of a sentence when making predictions. This mechanism helps capture dependencies between words, especially important in tasks like translation where word order may differ between languages.
- Self-Attention: The real innovation in transformers is self-attention, which helps the model focus on different words within a sentence when processing it. This is key to understanding the relationships between words in tasks beyond translation.
The combination of these features allows transformers to efficiently process and learn from large amounts of data, making them foundational for modern machine learning tasks in NLP and beyond.